TL; DR;
- 自宅サーバーのObservability基盤としてOpenTelemetryパイプラインを構築しました
- 複数の役割を持つコレクタにより実システムにも適用可能なスケーラブルなパイプラインを実現しました
- 特にTarget AllocatorによりPrometheusスクレイピングを重複なくスケール可能にしています
背景
我が家ではKubernetesクラスタを運用しておりObservabilityの仕組みとして、ログにはfluentd・メトリクスにはPrometheus/Grafanaを利用しています(トレースは未使用)。 1年近くこのスタックで運用してきましたが、ツールがばらけていることもあり、あまりログやメトリクスは上手く活用できていませんでした。
最近OpenTelemetryの資格を取ったこともあり、OpenTelemetryを利用してObservability基盤を再検討・構築してみることにしました。
アーキテクチャ
Observability基盤のアーキテクチャの要件は要件としては以下のように考えています。
- スケールすること
- パイプラインによるデータの変換・変更は集約した形で行えるようにすること
- ログはfluentdのやり方で変換・メトリクスはprometheus側で変換などだと運用負荷が高いので単一の仕組みで行いたい
- Kubernetes・ホストの情報をシグナルに付与できること
- テレメトリシグナルの保持・可視化を行うバックエンドツールに依存しないこと
これを踏まえ、以下のようなアーキテクチャとしました。
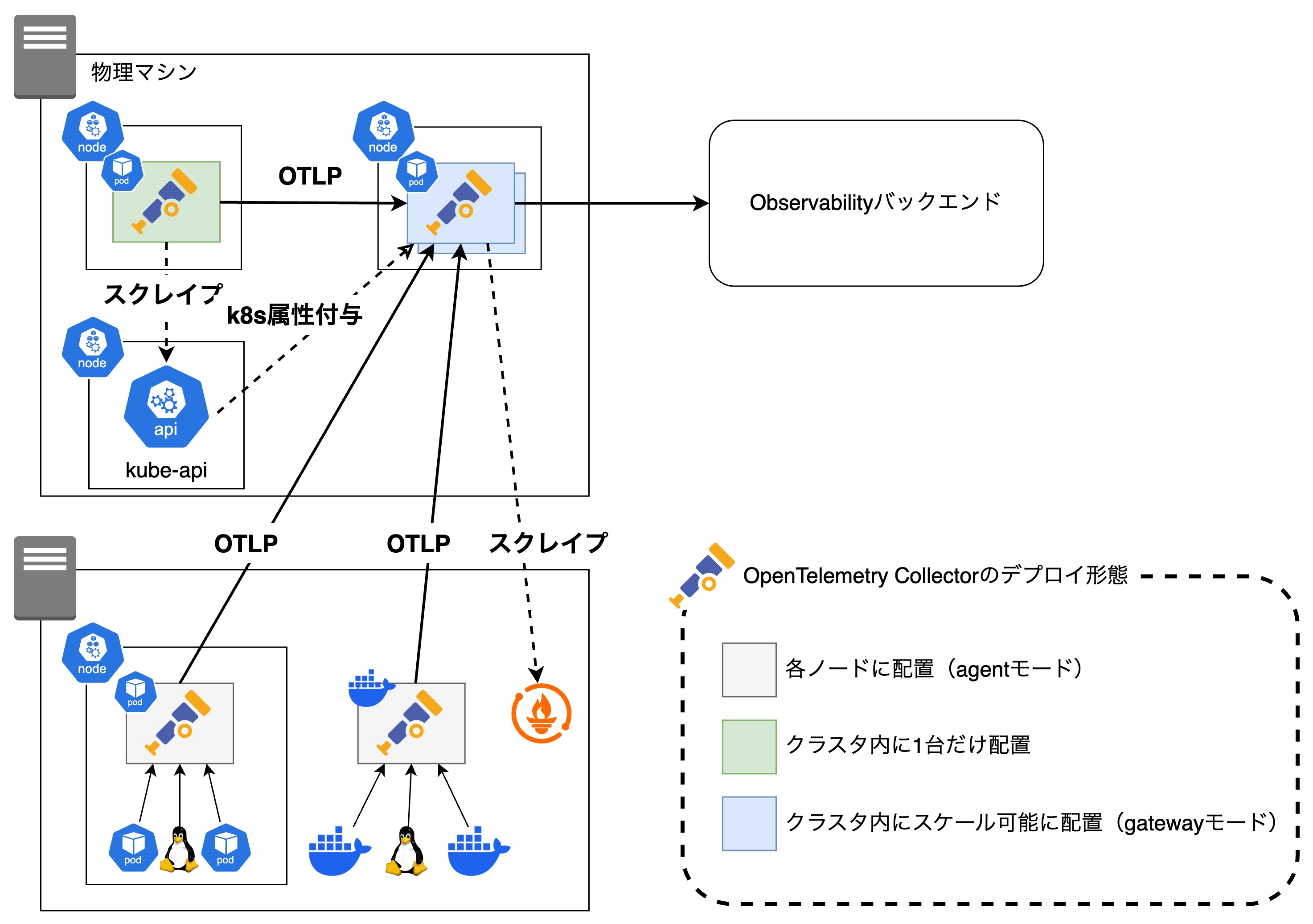
このアーキテクチャの特徴は3種類のOpenTelemetry Collectorを利用している点であり、公式ドキュメントで紹介されているagentとgatewayの組み合わせを参考にしています。 また、APM製品やベンダーから公開されているディストリビューションは使わず、OpenTelemetry公式のコレクタを利用することにしています。
agentコレクタ
まず、各ノード・物理マシンに1台ずつ配置するコレクタ(agent)は、各ノード上のPodからのログやノードそのもののメトリクスを収集します。 このコレクタで行うテレメトリシグナルの変換はノード固有の情報を付与することのみであり、本格的な変換は行いません。 また、agentを配置することによって、アプリケーションは自身のノード上のagentに対してシグナルを送信できるためデータのロスやアプリケーション側のオーバーヘッドを最低限にできます。
gatewayコレクタ
クラスタ内にスケール可能な形で配置するコレクタ(gateway)は、各コレクタからのデータを受け取り、共通して必要な情報の付与や変換を行ったのちにObservabilityバックエンドにデータを送信します。 また、prometheusでメトリクスを公開しているアプリケーションに対してはこのコレクタでスクレイプを行います。
gatewayコレクタにおいて重要なことは、クラスタ全体のテレメトリシグナル処理による負荷を考慮してスケーラビリティを確保することです。 とはいえ基本的にはコレクタから収集したデータをステートレスに処理するだけであるため、スケールアウトの障壁は高くはありません。 ただし例外もあって、その一つがメトリクスのスクレイピングです1。 スクレイピング設定を設定した状態でコレクタをスケールアウトすると、同じターゲットに対して複数のコレクタがスクレイピングを行うことになり、データが重複してしまいます。
これを防ぐために、OpenTelemetry OperatorによるTarget Allocatorを利用します。 Target Allocatorはあらかじめ取得したいメトリクスのターゲット一覧を取得し、それを各コレクタに割り振ります。 各コレクタはTarget Allocatorから自身が担当するターゲットの情報を取得し、それに従ってスクレイピングを行います。
クラスタに1つなコレクタ(clusteragentコレクタ)
このコレクタはクラスタ全体の情報のうち、gatewayコレクタを使ってスケールする形で取得できない情報を収集します。 例えばkubernetesクラスタのイベント情報が該当します。
clusteragentという名前にしていますがこれは公式による命名ではなく、cluster-wideなagentという意味で私が勝手に命名したものです。
構築
OpenTelemetry Collectorをデプロイするにあたっては、OpenTelemetry公式が用意しているOpenTelemetry Operatorを利用します。 このOperatorが提供しているOpenTelemetryCollectorというCustom Resourceを利用することで、簡単にOpenTelemetry Collectorをデプロイすることができます。
なおこの記事を書いている時点では、物理マシン上のagentコレクタ・k8sノードのOSログ収集の設定はまだ実装できていません(なので実は最初のアーキテクチャ図は一部未実装)。 ただしそれぞれ、
- Operatorの代わりにコンテナでデプロイする
- 取得するログを指定する
というだけで実装でき、パイプラインに多少追加が必要になるだけなので割愛します2。
Operatorのデプロイ
Operatorは公式ドキュメントに従ってマニフェストをapplyしてもいいですしHelm Chartを利用してもいいです。 私はArgoCDを利用しているので、Helm Chartを利用してデプロイしました。
Helm Chartでデプロイする場合にはvalues.yamlでコレクタ自体のイメージを指定することができます。 今回は下のように、k8sディストrビューションの最新版を指定しました。 contribなど他のディストリビューションやカスタムビルドのコレクタを利用したい場合にはここで指定します。
manager: # ... collectorImage: repository: "otel/opentelemetry-collector-k8s" tag: 0.122.1agentコレクタのデプロイ
agentコレクタ関連のマニフェスト
# agentコレクタ用のServiceAccountapiVersion: v1kind: ServiceAccountmetadata: namespace: monitoring name: agent-collector---
# agentコレクタ用のClusterRoleapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata: name: agent-collectorrules: # This is for k8s node resourcedetection processor # cf. https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/processor/resourcedetectionprocessor/README.md#k8s-node-metadata - apiGroups: [""] resources: ["nodes"] verbs: ["get", "list"] # This is for kubeletstats receiver - apiGroups: [""] resources: ["nodes/stats"] verbs: ["get"] # This is for cadvisor job of prometheus receiver - apiGroups: [""] resources: ["nodes"] verbs: ["watch"] - apiGroups: - '' resources: - nodes/proxy - nodes/metrics verbs: - get---
# agentコレクタ用のClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata: name: agent-collectorsubjects: - kind: ServiceAccount namespace: monitoring name: agent-collectorroleRef: kind: ClusterRole name: agent-collector apiGroup: rbac.authorization.k8s.io---
# agentコレクタ自体のマニフェストapiVersion: opentelemetry.io/v1beta1kind: OpenTelemetryCollectormetadata: name: agentspec: mode: daemonset serviceAccount: agent-collector
# This is for running on control plane nodes tolerations: - key: "node-role.kubernetes.io/control-plane" operator: Exists effect: NoSchedule - key: "node-role.kubernetes.io/master" operator: Exists effect: NoSchedule
volumeMounts: - name: varlogpods mountPath: /var/log/pods readOnly: true - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: hostfs mountPath: /hostfs readOnly: true mountPropagation: HostToContainer
volumes: # This is for filelog receiver - name: varlogpods hostPath: path: /var/log/pods # This is for filelog receiver - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers # This is for hostmetrics receiver - name: hostfs hostPath: path: /
env: - name: K8S_POD_IP valueFrom: fieldRef: apiVersion: v1 fieldPath: status.podIP - name: K8S_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName - name: K8S_NODE_IP valueFrom: fieldRef: fieldPath: status.hostIP # This is for resource detection from env processor - name: OTEL_RESOURCE_ATTRIBUTES value: "host.name=$(K8S_NODE_NAME),host.ip=$(K8S_NODE_IP)" - name: METRICS_SCRAPE_INTERVAL value: "1m"
config: receivers: prometheus/self: config: scrape_configs: - job_name: opentelemetry-collector scrape_interval: ${env:METRICS_SCRAPE_INTERVAL} static_configs: - targets: - ${env:K8S_POD_IP}:8888 labels: # This label must not be job, because this is not recognized as attribute job_label: opentelemetry-collector
prometheus: config: scrape_configs: - job_name: node-exporter scrape_interval: ${env:METRICS_SCRAPE_INTERVAL} static_configs: - targets: - ${env:K8S_NODE_IP}:9100 labels: job_label: node-exporter
# cf. https://github.com/newrelic/helm-charts/blob/master/charts/nr-k8s-otel-collector/collector.md#cadvisor - job_name: cadvisor scrape_interval: ${env:METRICS_SCRAPE_INTERVAL} bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token kubernetes_sd_configs: - role: node relabel_configs: - replacement: kubernetes.default.svc.cluster.local:443 target_label: __address__ - regex: (.+) replacement: /api/v1/nodes/$${1}/proxy/metrics/cadvisor source_labels: - __meta_kubernetes_node_name target_label: __metrics_path__ - action: replace target_label: job_label replacement: cadvisor - source_labels: [__meta_kubernetes_node_name] regex: ${K8S_NODE_NAME} action: keep scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false server_name: kubernetes
# cf. https://github.com/newrelic/helm-charts/blob/master/charts/nr-k8s-otel-collector/collector.md#kubelet - job_name: kubelet scrape_interval: ${env:METRICS_SCRAPE_INTERVAL} bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token kubernetes_sd_configs: - role: node relabel_configs: - replacement: kubernetes.default.svc.cluster.local:443 target_label: __address__ - regex: (.+) replacement: /api/v1/nodes/$${1}/proxy/metrics source_labels: - __meta_kubernetes_node_name target_label: __metrics_path__ - action: replace target_label: job_label replacement: kubelet - source_labels: [__meta_kubernetes_node_name] regex: ${K8S_NODE_NAME} action: keep scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false server_name: kubernetes
# cf. https://opentelemetry.io/docs/platforms/kubernetes/collector/components/#filelog-receiver filelog: include: - /var/log/pods/*/*/*.log exclude: # Exclude logs from all containers named otel-collector - /var/log/pods/*/otel-collector/*.log start_at: end include_file_path: true include_file_name: false operators: # parse container logs - type: container id: container-parser
# cf. https://github.com/newrelic/helm-charts/blob/master/charts/nr-k8s-otel-collector/collector.md#hostmetrics-receiver hostmetrics: root_path: /hostfs collection_interval: ${env:METRICS_SCRAPE_INTERVAL} scrapers: cpu: metrics: system.cpu.time: enabled: false system.cpu.utilization: enabled: true load: memory: metrics: system.memory.utilization: enabled: true paging: metrics: system.paging.utilization: enabled: false system.paging.faults: enabled: false filesystem: metrics: system.filesystem.utilization: enabled: true disk: metrics: system.disk.merged: enabled: false system.disk.pending_operations: enabled: false system.disk.weighted_io_time: enabled: false network: metrics: system.network.connections: enabled: false processes: process: metrics: process.cpu.utilization: enabled: true process.cpu.time: enabled: false mute_process_name_error: true mute_process_exe_error: true mute_process_io_error: true mute_process_user_error: true
# cf. https://github.com/newrelic/helm-charts/blob/master/charts/nr-k8s-otel-collector/collector.md#kubeletstats-receiver kubeletstats: collection_interval: ${env:METRICS_SCRAPE_INTERVAL} auth_type: "serviceAccount" endpoint: "https://${env:K8S_NODE_IP}:10250" insecure_skip_verify: true metrics: # This rename cpu utilization to cpu usage k8s.node.cpu.utilization: enabled: false k8s.node.cpu.usage: enabled: true k8s.pod.cpu.utilization: enabled: false k8s.pod.cpu.usage: enabled: true container.cpu.utilization: enabled: false container.cpu.usage: enabled: true
processors: batch: {}
memory_limiter: # This value if from example in the documentation # https://github.com/open-telemetry/opentelemetry-collector/blob/main/processor/memorylimiterprocessor/README.md check_interval: 1s limit_percentage: 80 spike_limit_percentage: 15
attributes/job_label_hostmetrics: actions: - key: job_label action: upsert value: hostmetrics
attributes/job_label_kubeletstats: actions: - key: job_label action: upsert value: kubeletstats
# cf. https://opentelemetry.io/docs/platforms/kubernetes/collector/components/#kubernetes-attributes-processor k8sattributes: # cf. https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/processor/k8sattributesprocessor/README.md#as-a-gateway passthrough: true
# cf. https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/processor/resourcedetectionprocessor/README.md#k8s-node-metadata resourcedetection/k8snode: detectors: [k8snode] k8snode: node_from_env_var: "K8S_NODE_NAME"
# Because system detector cannot be used in container for host detection, extract from env manually resourcedetection/env: detectors: [env]
# This is for pod annotation adding in gateway collector resource/append_pod_ip: attributes: - key: k8s.pod.ip action: insert value: ${env:K8S_POD_IP}
connectors: routing/metrics_common: table: - condition: "true" pipelines: - metrics
exporters: otlp: endpoint: gateway-collector:4317 tls: insecure: true
service: pipelines: logs: receivers: - filelog processors: - memory_limiter - batch - k8sattributes - resourcedetection/k8snode - resourcedetection/env exporters: - otlp
metrics/hostmetrics: receivers: - hostmetrics processors: - attributes/job_label_hostmetrics exporters: - routing/metrics_common
metrics/kubeletstats: receivers: - kubeletstats processors: - attributes/job_label_kubeletstats exporters: - routing/metrics_common
metrics/self: receivers: - prometheus/self processors: - resource/append_pod_ip exporters: - routing/metrics_common
metrics: receivers: - routing/metrics_common - prometheus processors: - memory_limiter - batch - k8sattributes - resourcedetection/k8snode - resourcedetection/env exporters: - otlp telemetry: metrics: readers: - pull: exporter: prometheus: host: ${env:K8S_POD_IP} port: 8888一つ一つの設定を説明していると長くなるので、マニフェスト自体は折りたたみますが、agentコレクタのパイプラインは以下のようになっています。
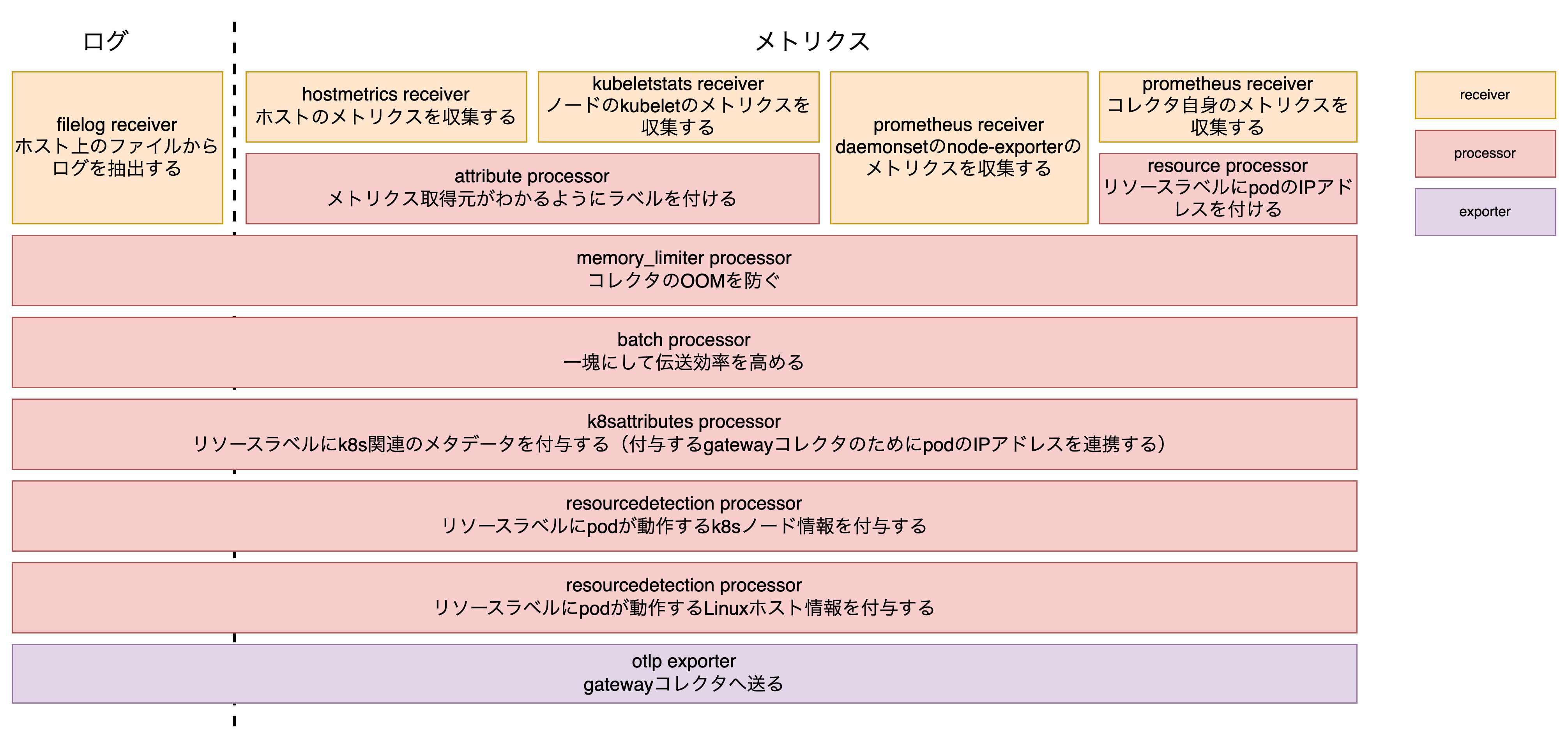
このアーキテクチャにおいてagentコレクタはノードの情報を付与することに徹しているため、そのためのprocessorが連なっています。
基本的にはやっていることはシンプルですが、k8sattributes processorは説明がないとわかりにくいので説明をします。
processorの設定自体は下のように非常にシンプルとなっており、実際にagentコレクタではpodのIPアドレスを付与することしか行っていません。
k8sattributes: passthrough: trueというのも、公式ドキュメントにあるように、gateway/agent形式でパイプラインを構築する場合には全コレクタがメタデータ付与のためにAPIサーバーにアクセスして高負荷になるのを避けるために以下の2つのどちらかの設定が推奨されているためです。
- agentコレクタにおいて自ノードに関するメタデータのみにアクセスするようにフィルタリングする
- 実際にAPIサーバーにアクセスしメタデータを付与するのはgatewayコレクタのみにする
- gatewayではpodのIPアドレスが不明なためagentコレクタはpodのIPを連携する
今回はgatewayコレクタをスケーラブルにするといってもagentよりは数が少ない見込みなこと、gatewayでまとめて行えばキャッシュなどが効いたりするかもという期待から後者を採用しました。
gatewayコレクタのデプロイ
gatewayコレクタ関連のマニフェスト
# gatewayコレクタ用のServiceAccountapiVersion: v1kind: ServiceAccountmetadata: namespace: monitoring name: gateway-collector---
# gatewayコレクタ用のClusterRoleapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata: name: gateway-collectorrules: # This is for k8sattributes processor # cf. https://opentelemetry.io/docs/platforms/kubernetes/collector/components/#kubernetes-attributes-processor - apiGroups: - '' resources: - 'pods' - 'namespaces' verbs: - 'get' - 'watch' - 'list' - apiGroups: - 'apps' resources: - 'replicasets' verbs: - 'get' - 'list' - 'watch' - apiGroups: - 'extensions' resources: - 'replicasets' verbs: - 'get' - 'list' - 'watch' # This rule is for apiserver job of prometheus receiver # cf. https://sysdig.jp/blog/monitor-kubernetes-api-server/ - nonResourceURLs: - /metrics verbs: - get---
# gatewayコレクタ用のClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata: name: gateway-collectorsubjects: - kind: ServiceAccount namespace: monitoring name: gateway-collectorroleRef: kind: ClusterRole name: gateway-collector apiGroup: rbac.authorization.k8s.io---
# gatewayコレクタのTarget Allocator用のServiceAccountapiVersion: v1kind: ServiceAccountmetadata: namespace: monitoring name: gateway-target-allocator---
# gatewayコレクタのTarget Allocator用のClusterRoleapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata: name: gateway-target-allocatorrules: # This is for target allocation of kube-state-metrics - apiGroups: - '' resources: - 'pods' verbs: - 'list' - 'watch' # This is for target allocation of api-server - apiGroups: - '' resources: - 'endpoints' - 'services' verbs: - 'list' - 'watch'---
# gatewayコレクタのTarget Allocator用のClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata: name: gateway-target-allocatorsubjects: - kind: ServiceAccount namespace: monitoring name: gateway-target-allocatorroleRef: kind: ClusterRole name: gateway-target-allocator apiGroup: rbac.authorization.k8s.io---
# gatewayコレクタ自体のマニフェストapiVersion: opentelemetry.io/v1beta1kind: OpenTelemetryCollectormetadata: name: gatewayspec: # Deployment mode does not support target allocator mode: statefulset targetAllocator: enabled: true serviceAccount: gateway-target-allocator
serviceAccount: gateway-collector
env: - name: K8S_POD_IP valueFrom: fieldRef: apiVersion: v1 fieldPath: status.podIP - name: METRICS_SCRAPE_INTERVAL value: "1m"
config: receivers: otlp: protocols: grpc: endpoint: ${env:K8S_POD_IP}:4317
prometheus/self: config: scrape_configs: - job_name: opentelemetry-collector scrape_interval: "${env:METRICS_SCRAPE_INTERVAL}" static_configs: - targets: - ${env:K8S_POD_IP}:8888 labels: # This label must not be job, because this is not recognized as attribute job_label: opentelemetry-collector
prometheus: config: global: # Currently, target allocator config seems not to recognize environment variables # cf. https://github.com/open-telemetry/opentelemetry-operator/issues/2257 scrape_interval: "1m" scrape_configs:
- job_name: node-exporter dns_sd_configs: - type: SRV names: - _node-exporter._tcp.lab.kotaro7750.net relabel_configs: - action: replace target_label: job_label replacement: node-exporter
# cf. https://github.com/newrelic/helm-charts/blob/master/charts/nr-k8s-otel-collector/collector.md#kube-state-metrics - job_name: kube-state-metrics kubernetes_sd_configs: - role: pod relabel_configs: - action: keep regex: kube-state-metrics source_labels: - __meta_kubernetes_pod_label_app_kubernetes_io_name - action: replace target_label: job_label replacement: kube-state-metrics
# cf. https://github.com/newrelic/helm-charts/blob/master/charts/nr-k8s-otel-collector/collector.md#apiserver - job_name: apiserver kubernetes_sd_configs: - role: endpoints namespaces: names: - default scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: keep regex: default;kubernetes;https source_labels: - __meta_kubernetes_namespace - __meta_kubernetes_service_name - __meta_kubernetes_endpoint_port_name - action: replace source_labels: - __meta_kubernetes_namespace target_label: namespace - action: replace source_labels: - __meta_kubernetes_service_name target_label: service - action: replace target_label: job_label replacement: apiserver
# cf. https://github.com/newrelic/helm-charts/blob/master/charts/nr-k8s-otel-collector/collector.md#controller-manager - job_name: controller-manager metrics_path: /metrics kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: keep regex: default;kubernetes;https source_labels: - __meta_kubernetes_namespace - __meta_kubernetes_service_name - __meta_kubernetes_endpoint_port_name - action: replace source_labels: - __meta_kubernetes_namespace target_label: namespace - action: replace source_labels: - __meta_kubernetes_pod_name target_label: pod - action: replace source_labels: - __meta_kubernetes_service_name target_label: service - action: replace target_label: job_label replacement: controller-manager
# cf. https://github.com/newrelic/helm-charts/blob/master/charts/nr-k8s-otel-collector/collector.md#scheduler - job_name: scheduler kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: keep regex: default;kubernetes;https source_labels: - __meta_kubernetes_namespace - __meta_kubernetes_service_name - __meta_kubernetes_endpoint_port_name - action: replace source_labels: - __meta_kubernetes_namespace target_label: namespace - action: replace source_labels: - __meta_kubernetes_service_name target_label: service - action: replace target_label: job_label replacement: scheduler
processors: batch: {} memory_limiter: # This value if from example in the documentation # https://github.com/open-telemetry/opentelemetry-collector/blob/main/processor/memorylimiterprocessor/README.md check_interval: 1s limit_percentage: 80 spike_limit_percentage: 15
# cf. https://opentelemetry.io/docs/platforms/kubernetes/collector/components/#kubernetes-attributes-processor # k8s attributes processor on gateway collector can be used when pod ip is received from agent collector # cf. https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/processor/k8sattributesprocessor/README.md#as-a-gateway k8sattributes: auth_type: 'serviceAccount' extract: metadata: # extracted from the pod - k8s.namespace.name - k8s.pod.name - k8s.pod.start_time - k8s.pod.uid - k8s.deployment.name - k8s.daemonset.name - k8s.statefulset.name - k8s.cronjob.name - k8s.job.name - k8s.node.name pod_association: - sources: # First try to use the value of the resource attribute k8s.pod.ip - from: resource_attribute name: k8s.pod.ip - sources: # Then try to use the value of the resource attribute k8s.pod.uid - from: resource_attribute name: k8s.pod.uid - sources: # If neither of those work, use the request's connection to get the pod IP. - from: connection
resource/append_pod_ip: attributes: - key: k8s.pod.ip action: insert value: ${env:K8S_POD_IP}
resource/delete_pod_ip: attributes: - key: k8s.pod.ip action: delete
resource/append_environment_info: attributes: - key: k8s.cluster.name value: lab-production action: upsert - key: deployment.environment.name value: production action: upsert
resource/new_relic: attributes: - key: newrelicOnly action: upsert value: 'true' - key: service.name action: delete - key: service_name action: delete
# This is for NewRelic # cf. https://github.com/newrelic/helm-charts/blob/master/charts/nr-k8s-otel-collector/collector.md#processors metricstransform/k8s_cluster_info: transforms: - include: kubernetes_build_info action: update new_name: k8s.cluster.info
# This is for NewRelic metricstransform/kube_pod_status_phase: transforms: - include: 'kube_pod_container_status_waiting' match_type: strict action: update new_name: 'kube_pod_container_status_phase' operations: - action: add_label new_label: container_phase new_value: waiting - include: 'kube_pod_container_status_running' match_type: strict action: update new_name: 'kube_pod_container_status_phase' operations: - action: add_label new_label: container_phase new_value: running - include: 'kube_pod_container_status_terminated' match_type: strict action: update new_name: 'kube_pod_container_status_phase' operations: - action: add_label new_label: container_phase new_value: terminated
# This is for NewRelic metricstransform/hostmetrics_cpu: transforms: - include: system.cpu.utilization action: update operations: - action: aggregate_labels label_set: # Only exclude cpu attribute - state - host_ip - k8s_node_uid - host_name - k8s_node_name - job_label - k8s_cluster_name - deployment_environment_name aggregation_type: mean - include: system.paging.operations action: update operations: - action: aggregate_labels label_set: [ direction ] aggregation_type: sum
exporters: otlp/signoz: endpoint: 172.16.1.59:4317 tls: insecure: true otlphttp/new_relic: endpoint: https://otlp.nr-data.net:4318 headers: api-key: "1e249af1eea27fa5ee8304a883a86f14FFFFNRAL"
connectors: routing/metrics_common: table: - condition: "true" pipelines: - metrics
routing/metrics_per_backend: table: - condition: "true" pipelines: - metrics/new_relic
routing/logs_per_backend: table: - condition: "true" pipelines: - logs/new_relic
routing/traces_per_backend: table: - condition: "true" pipelines: - traces/new_relic
service: pipelines: traces: receivers: [otlp] processors: - memory_limiter - batch - k8sattributes - resource/delete_pod_ip - resource/append_environment_info exporters: - routing/traces_per_backend
traces/new_relic: receivers: - routing/traces_per_backend processors: - resource/new_relic exporters: - otlp/signoz # - otlphttp/new_relic
logs: receivers: [otlp] processors: - memory_limiter - batch - k8sattributes - resource/delete_pod_ip - resource/append_environment_info exporters: - routing/logs_per_backend
logs/new_relic: receivers: - routing/logs_per_backend processors: - resource/new_relic exporters: - otlp/signoz # - otlphttp/new_relic
metrics/self: receivers: - prometheus/self processors: - resource/append_pod_ip exporters: - routing/metrics_common
metrics: receivers: - otlp - prometheus - routing/metrics_common processors: - memory_limiter - batch - k8sattributes - resource/delete_pod_ip - resource/append_environment_info exporters: - routing/metrics_per_backend
metrics/new_relic: receivers: - routing/metrics_per_backend processors: - resource/new_relic - metricstransform/k8s_cluster_info - metricstransform/kube_pod_status_phase - metricstransform/hostmetrics_cpu exporters: - otlp/signoz # - otlphttp/new_relic
telemetry: metrics: readers: - pull: exporter: prometheus: host: ${env:K8S_POD_IP} port: 8888今回のパイプラインでもっとも複雑なのがgatewayコレクタです。 そのため、画像でも多少省略している部分があります。
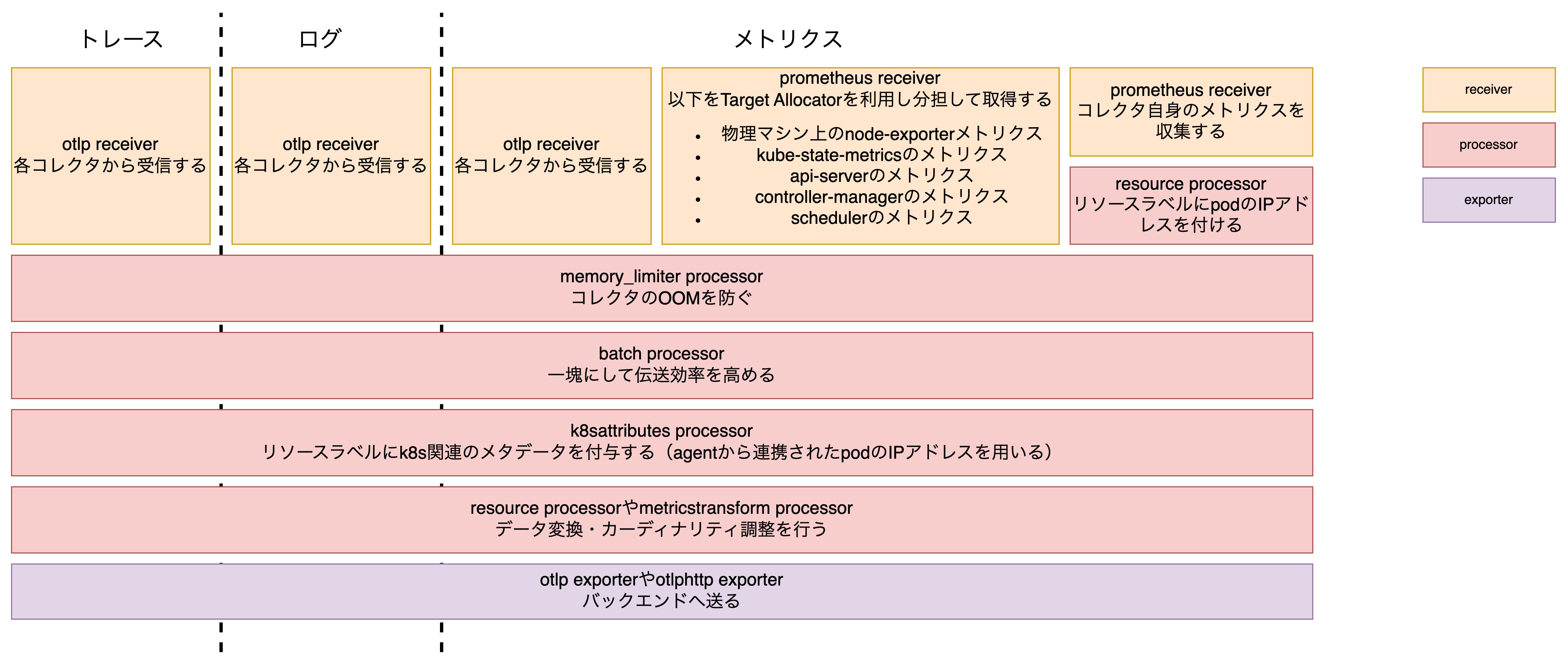
gatewayコレクタにおいて重要な点は以下の3つです。
- kubernetesのメタデータを実際に付与している
- バックエンドに応じてデータを変換する
- Target Allocatorを利用してスケーラブルにしている
1つ目に関しては、agentコレクタの部分でも説明したように、k8sattributes processorによるAPIサーバーに対する負荷を考慮してgatewayコレクタでまとめてメタデータを付与しているというものです。
2つ目に関しては、各バックエンド(このマニフェストではNewRelicを想定)に応じてデータの変換を行うというものです。 製品によっては必要なメタデータやメトリクスが異なりますが、実際にバックエンドに送る直前にデータの変換を行うことでバックエンドの仕様変更・追加に柔軟に対応できるようにしています。 また、コストの観点からもそれぞれに応じてメトリクスを減らしたりラベルのカーディナリティを減らすことでコスト削減も可能にします3。
3つ目については次のセクションで説明します。
clusteragentコレクタのデプロイ
clusteragentコレクタ関連のマニフェスト
# clusteragentコレクタ用のServiceAccountapiVersion: v1kind: ServiceAccountmetadata: namespace: monitoring name: clusteragent-collector---
# clusteragentコレクタ用のClusterRoleapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata: name: clusteragent-collectorrules: # This is for k8s_events receiver # cf. https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/k8seventsreceiver - apiGroups: - "" resources: - events - namespaces - namespaces/status - nodes - nodes/spec - pods - pods/status - replicationcontrollers - replicationcontrollers/status - resourcequotas - services verbs: - get - list - watch - apiGroups: - apps resources: - daemonsets - deployments - replicasets - statefulsets verbs: - get - list - watch - apiGroups: - extensions resources: - daemonsets - deployments - replicasets verbs: - get - list - watch - apiGroups: - batch resources: - jobs - cronjobs verbs: - get - list - watch - apiGroups: - autoscaling resources: - horizontalpodautoscalers verbs: - get - list - watch---
# clusteragentコレクタ用のClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata: name: clusteragent-collectorsubjects: - kind: ServiceAccount namespace: monitoring name: clusteragent-collectorroleRef: kind: ClusterRole name: clusteragent-collector apiGroup: rbac.authorization.k8s.io---
# clusteragentコレクタ自体のマニフェストapiVersion: opentelemetry.io/v1beta1kind: OpenTelemetryCollectormetadata: name: clusteragentspec: mode: deployment serviceAccount: clusteragent-collector # This collector is for cluster-wide telemetry but not scalable with target allocator, so replicas must be 1 for avoiding duplication replicas: 1
env: - name: K8S_POD_IP valueFrom: fieldRef: apiVersion: v1 fieldPath: status.podIP - name: METRICS_SCRAPE_INTERVAL value: "1m"
config: receivers: k8s_events: {}
prometheus: config: scrape_configs: - job_name: opentelemetry-collector scrape_interval: ${env:METRICS_SCRAPE_INTERVAL} static_configs: - targets: - ${env:K8S_POD_IP}:8888 labels: # This label must not be job, because this is not recognized as attribute job_label: opentelemetry-collector
processors: batch: {} memory_limiter: # This value if from example in the documentation # https://github.com/open-telemetry/opentelemetry-collector/blob/main/processor/memorylimiterprocessor/README.md check_interval: 1s limit_percentage: 80 spike_limit_percentage: 15
# This is for pod annotation adding in gateway collector resource/append_pod_ip: attributes: - key: k8s.pod.ip action: insert value: ${env:K8S_POD_IP}
exporters: otlp: endpoint: gateway-collector:4317 tls: insecure: true
connectors: routing/metrics_common: table: - condition: "true" pipelines: - metrics
service: pipelines: logs: receivers: [k8s_events] processors: - memory_limiter - batch exporters: [otlp]
metrics/prometheus: receivers: - prometheus processors: - resource/append_pod_ip exporters: - routing/metrics_common
metrics: receivers: - routing/metrics_common processors: - memory_limiter - batch exporters: [otlp]
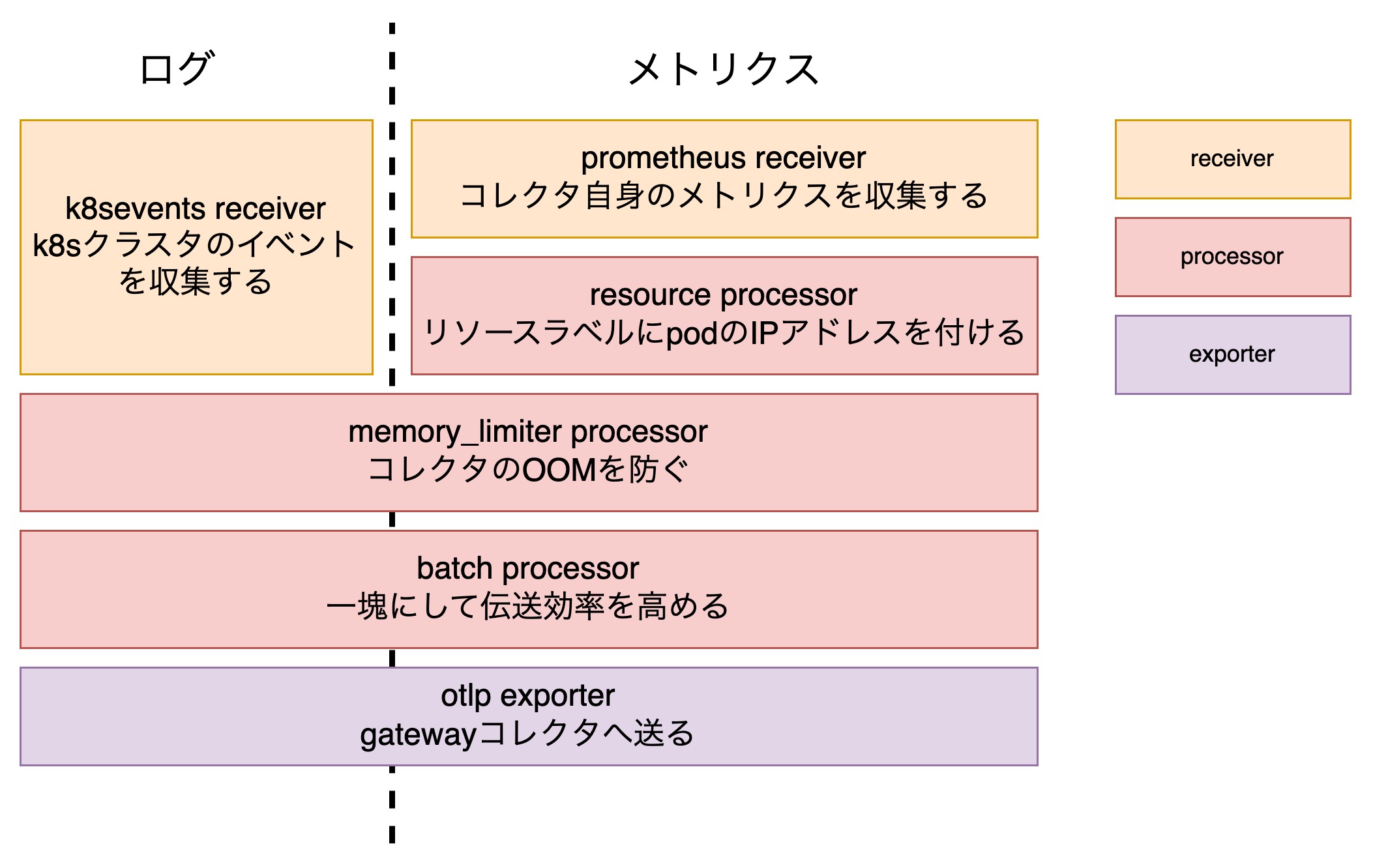
telemetry: metrics: readers: - pull: exporter: prometheus: host: ${env:K8S_POD_IP} port: 8888アーキテクチャセクションで記載したようにclusteragentコレクタではTarget Allocatorを利用できないが重複を避けたいシグナルを取得しています。 そのためdeploymentのレプリカ数は1にしています。
パイプラインとしては非常にシンプルで、k8sevents receiverでk8sのイベントを取得するのみを担当しています。 k8sのイベントを1つのコレクタで取得している時点でスケールしないのでは?と思うかもしれませんが、メトリクスと比較すると軽量である見込みが高いためこのような構成としています4。
Target AllocatorによるPrometheusスクレイプ分散
今回のアーキテクチャでもっとも重要な部分ともいえるのが、gatewayコレクタのTarget Allocatorによるprometheusメトリクスの分担スクレイプです。 これにより、メトリクスの重複なしにコレクタをスケールすることが可能になります。
公式ドキュメントから引用した以下の図に示すように、Target Allocatorがスクレイプ対象のメトリクスを各コレクタに割り振り、各コレクタがそれを参照してスクレイプすることで分担を可能にしています。
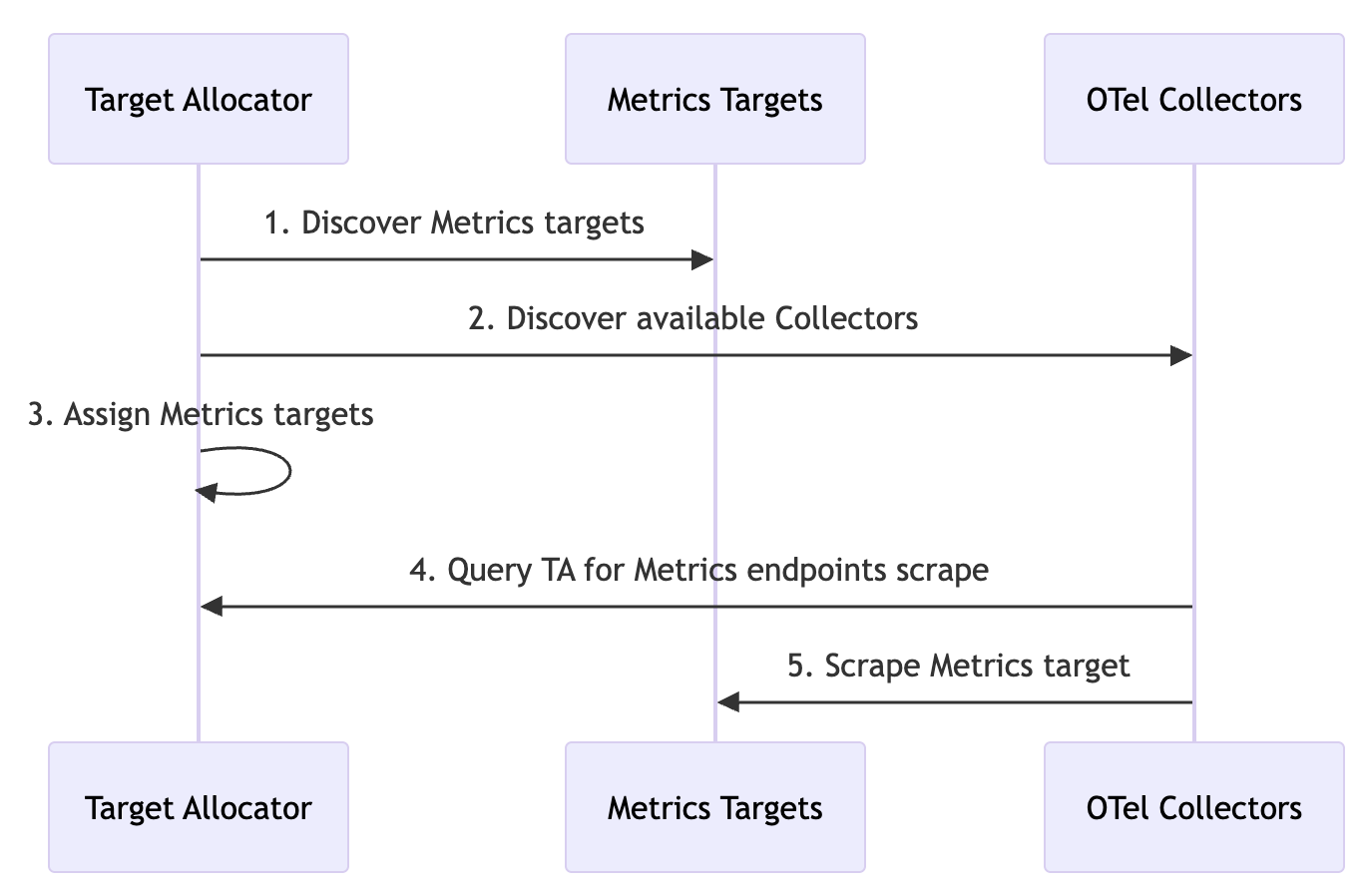
何やら複雑な仕組みですが、実際に行う必要のある設定は以下のようにyamlに数行各程度であり、スクレイプ設定自体はTarget Allocatorを使わない場合と全く同じです。
spec: # deploymentモードはTarget Allocatorを利用できないので注意 mode: statefulset targetAllocator: enabled: true serviceAccount: gateway-target-allocatorなお、公式ドキュメントにはデバッグの方法が書かれており、Target Allocatorに対し実際に分担されたターゲットを参照することができます。
実際に参照した例が下で、apiサーバーへのスクレイプは1つ目のレプリカに割り振られ、kube-state-metricsへのスクレイプはもう一つのレプリカに割り振られていることがわかります。
// あらかじめTarget AllocatorのServiceに対してport-forwardしておく// kubectl port-forward svc/otelcol-targetallocator -n opentelemetry 8080:80
// curl localhost:8080/jobs{ "apiserver": { "_link": "/jobs/apiserver/targets" }, "kube-state-metrics": { "_link": "/jobs/kube-state-metrics/targets" } // ...}
// curl localhost:8080/jobs/apiserver/targets{ "gateway-collector-0": { "_link": "/jobs/apiserver/targets?collector_id=gateway-collector-0", "targets": [ { "targets": [ "172.16.1.7:6443" ], "labels": { "__address__": "172.16.1.7:6443", "__meta_kubernetes_endpoint_port_name": "https", // ... "__meta_kubernetes_service_name": "kubernetes" } } ] }, "gateway-collector-1": { "_link": "/jobs/apiserver/targets?collector_id=gateway-collector-1", "targets": [] }}// curl localhost:8080/jobs/kube-state-metrics/targets{ "gateway-collector-0": { "_link": "/jobs/kube-state-metrics/targets?collector_id=gateway-collector-0", "targets": [] }, "gateway-collector-1": { "_link": "/jobs/kube-state-metrics/targets?collector_id=gateway-collector-1", "targets": [ { "targets": [ "10.0.1.251:8080" ], "labels": { "__address__": "10.0.1.251:8080", "__meta_kubernetes_namespace": "monitoring", "__meta_kubernetes_pod_container_id": "containerd://46c6a053c90e445464ac3d3ef41b5039ffba591c145976dc50ad3e8ee2269a0d", // ... "__meta_kubernetes_pod_uid": "285e7b4e-8b28-4a6d-8a32-d1ba302eeba9" } } ] }}なお、今回は利用していませんが、Target AllocatorはPrometheus OperatorのCustom Resourceを参照する機能も持っています。
可視化による確認
実際にデプロイした後は、Observabilityバックエンドにデータを送信して可視化してみます。 今回はNewRelicとSigNozを利用してみました5。
実際に活用するためにはそれぞれに応じてデータの変換を調整する必要がありますが、同じパイプラインで異なるバックエンドにデータを送信することができています。
まとめ
この記事では、自宅サーバー環境に統一的・スケーラブルなObservabilityパイプラインを構築しました。
今後はこのアーキテクチャをベースに、Observabilityの強化を図っていきたいです。
Footnotes
-
その他にはtail baseサンプリング(特定の条件を満たすトレーススパンのみをサンプルする機能)があります。 これを行うためには同じトレースIDを持つスパンを同じコレクタで処理する必要があります。 この記事では紹介しませんが、これを実現する手段としてload-balancing-exporterを利用することができます。 ↩
-
割愛とお茶を濁していますが実際には記事を書いている時に気づきました。 特に前者は自分の場合ちゃんとAnsibleプレイブックを書かないといけなく、労力の割に話題としては重要ではないということもあり先に記事を書いています。 そのうち別記事として追加するかも。 ↩
-
この設定はNewRelicのドキュメントを参考にしていますが、必要十分なメトリクス・カーディナリティの調整は検証しきれていないので、あくまでも参考程度にしてください。 ↩
-
とはいえ全くもってスケールできないわけではなく、取得対象のnamespaceを分担すればスケールが可能です。 ただしその場合対象のnamespaceの指定を行う必要があり、特に何も考えないと別々の設定ファイルを使うことに繋がるためやるにしても何らかの仕組みがないと運用が面倒になります。 ↩
-
SigNozはDatadogよりもコスト効率が良いと謳っているOSSのAPMツールで、OpenTelemetryネイティブを標榜しており、docker composeで簡単に立ち上げられるため検証には便利です。 ↩