TL; DR;
- 宅鯖のLLM基盤用にLiteLLMをLLM・MCPゲートウェイとしてKubernetesにデプロイしました
- 永続化用のDBを常時稼働させるとコストが気になるため、Aurora Serverlessを活用し利用時だけオンデマンドに起動する構成を目指しました
- KEDAの標準scalerだけでは表現しづらい起動条件を扱うため、時間限定の起動要求を送れるExternal Push scalerを実装しました
- Slack Appも自作し、スラッシュコマンドからLiteLLMを起動できるようにしました
- 結果的に月700円程度のコストオーバーヘッドでLLM基盤を構築できました
背景
我が家の宅鯖にもAIの波がやってきており、LLMワークロードを動かしたいと思う場面も出てきました。
LLMワークロードを扱うにあたっての最近のトレンドとして、各ワークロードが直接LLMプロバイダーのAPIを叩くのではなく、共通のゲートウェイを1つ置いてそこに集約する、という形が多いと感じています。 これによって、コスト管理・APIトークン管理・アクセス制御・監査の一元化がしやすくなる他、異なるプロバイダーを同じインターフェースで扱えるようになるというメリットもあります。
そこで今回は、LiteLLMというOSSを自宅のKubernetesクラスタにデプロイしてLLM・MCPゲートウェイとして動かすことにしました。 このOSSはOpenAI・Anthropic・Geminiなど複数のプロバイダーをOpenAI互換のインターフェースで扱うことができる他、最近はMCPやA2Aプロキシ機能も拡充されています。
LiteLLMではAPIキーによる認証認可やユーザー毎の管理機能を利用するには外部のPostgreSQL互換DBが必要です。 今回はDBとしてAWSを利用することにしましたが1、問題になってくるのがコストです。
表は東京リージョンで最低構成のDBを1ヶ月維持した際のおおよそのコスト感ですが、いずれの製品も常時稼働させると月3,000円以上となってしまいます。 最近のサブスクサービスと同じくらいのお金を払って得られるものはLLMゲートウェイの永続化だけ、というのはいささかコスパが悪いです。
| 製品 | 最低コスト(東京リージョン) |
|---|---|
| Lightsail DB | $15/月 |
| RDS for PostgreSQL | 約$20/月 |
| Aurora Serverless for PostgreSQL | $54/月 + ストレージIO |
| Aurora for PostgreSQL | 約$80/月 + ストレージIO |
宅鯖という性質上、人間によるアクセスは夜間や休日が中心であり、定期ジョブなども頻繁に走るわけではないためLLM基盤の利用はかなりスパースであることが想定されます。 そのため、今回は使っていない時間はLiteLLMもDBも両方とも寝かせておいて、必要な時だけ起こす構成を目指すことにしました。
目指す構成
この構成を行うことを踏まえ、今回はDBとしてAurora Serverlessを選択しました。 Aurora Serverlessは最新のバージョンではACUを0までスケールインすることができ、起動や停止をアクセス状態に応じて自動で行ってくれるため、起動停止処理を自分で実装する必要がありません。
これを利用して今回は、DBアクセスを行うLiteLLM自体を必要な時だけ起動する構成を目指します。 つまり、LLMを使うワークロードが動くときにLiteLLMが起き、その後LiteLLMからAuroraへ接続が発生した時点でAuroraも復帰する、という流れにしたいわけです。
また、起動トリガはアプリケーションだけではありません。 手元で検証したいときや、GUIクライアントやMCPクライアントからLiteLLMを使いたいときには、人間が明示的に起動できる導線もほしくなります。 今回はその入口としてSlack Appを用意し、スラッシュコマンドからLiteLLMを起動できるようにしました。
全体の構成としては、以下のようなイメージになります。
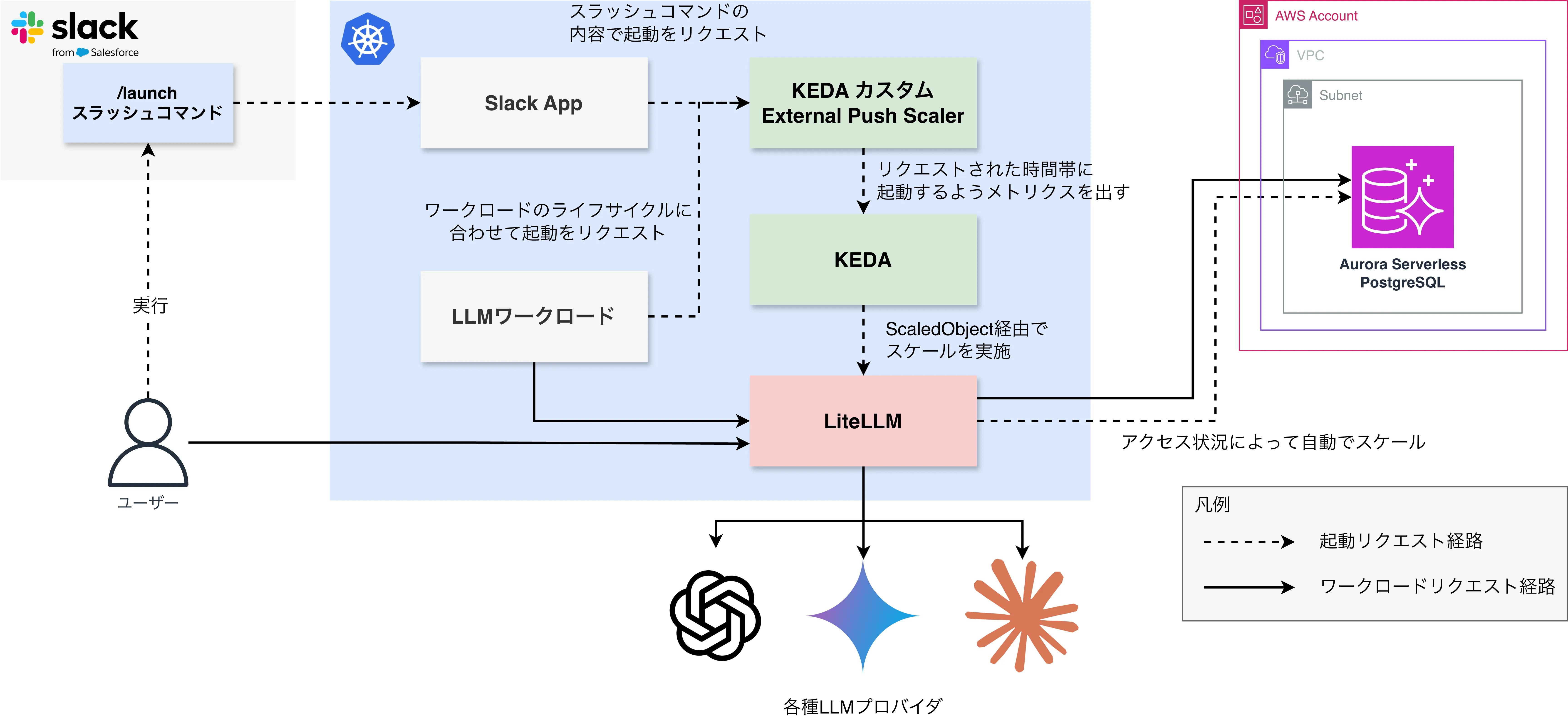
この構成の肝は、ワークロード起点の自動起動とSlack起点の手動起動の両方で活用される自作のKEDA External Push scalerです。 詳しくは後述しますが、リクエストされた時間だけ対象のワークロード(今回はLiteLLM)をスケールアウトさせる仕組みを実現するためのコンポーネントです。
LiteLLMとAurora Serverless
LiteLLMはKubernetes上ではHelmチャート経由でDeploymentとして動かしています。 LiteLLM自体の設定はあまり工夫した部分は少ないですが、DBにモデルを保存したり、仮想APIキーを発行できるようにTerraformで管理しています。
# LiteLLMの設定例proxy_config: model_list: [] # モデル管理はTerraform経由のため空 general_settings: store_model_in_db: true # UIから見えるログはDBを圧迫するので無効にする disable_spend_logs: true disable_error_logs: true litellm_settings: callbacks: ["datadog_llm_observability", "otel"] # Observabilityの設定(後述)Terraformによるモデル・ユーザー管理のサンプル
# AIプロバイダへの共有クレデンシャルresource "litellm_credential" "google-ai-studio" { credential_name = "google-ai-studio"
credential_values = { api_key = APIキー }
credential_info = { custom_llm_provider = "Google_AI_Studio" }}
# LiteLLMで利用するLLMモデル(下は無料枠でのGoogle AI StudioのGemini 2.5 Flash)resource "litellm_model" "gemini_2_5_flash" { model_name = "gemini-2.5-flash-free" base_model = "gemini-2.5-flash" custom_llm_provider = "gemini" litellm_credential_name = litellm_credential.google-ai-studio.credential_name
tier = "free" mode = "chat"
input_cost_per_million_tokens = 0.0 output_cost_per_million_tokens = 0.0}
# ワークロードがLiteLLMにアクセスする際のAPIキー発行resource "litellm_key" "some_llm_workload" { key_alias = "some_llm_workload"}LiteLLMの永続化先のAurora ServerlessもTerraformで管理しています。
resource "aws_rds_cluster" "cluster" { engine = "aurora-postgresql" engine_version = "17.7" engine_mode = "provisioned" # serverlessとしてしまうとv1となってしまうので注意
# Aurora Serverless v2のスケール設定 serverlessv2_scaling_configuration { min_capacity = 0.0 # 0にしておくことでアクセスがない際に自動で停止できる max_capacity = 1.0 seconds_until_auto_pause = 300 # 5分アクセスがないと自動で停止 }}
resource "aws_rds_cluster_instance" "cluster_instance" { cluster_identifier = aws_rds_cluster.cluster.id instance_class = "db.serverless" engine = aws_rds_cluster.cluster.engine engine_version = aws_rds_cluster.cluster.engine_version db_subnet_group_name = aws_rds_cluster.cluster.db_subnet_group_name
publicly_accessible = true # 自宅から接続するためにインターネット公開する}最小ACUを0にしておくことでアクセスがない時には自動で停止してACU分のコストを抑えられるようにします。 注意点として、あくまでも0になるのはACUコストであってストレージコストはかかります。 また、アクセスがないというのはクエリがないということではなく接続がないということを意味するため、停止状態にしたい場合にはLiteLLM側もスケールダウンして接続がなされない状態にする必要があります。
KEDAによるLiteLLMのオンデマンド起動
上記のようにAurora Serverlessの0スケール機能を活かすためにはLiteLLM側でも必要な時だけ起動しそれ以外は停止させる必要があります。
Kubernetesワークロードの水平スケールとしては組み込みのHorizontal Pod Autoscaler (HPA)が第一候補ですが、HPAはあくまでもPodあたりのメトリクスを閾値に収めるという目的であり、今回のように基本的には0レプリカで必要な時だけ起動するという要件にはあまり向いていません。
そこで出てくるのがKEDAというOSSです。
KEDAはHPAを拡張したScaledObject CRDのコントローラーとして、様々なイベントをトリガーとして水平スケールを行うことができる仕組みを提供しています。
さらにKEDAはスケールダウンの際にPodを完全に削除して0レプリカにすることもできるため、今回のようなオンデマンド起動構成には非常に相性が良いです。
トリガーは組み込みで様々なものがあり、時刻によるスケジュールができるCronやSQSのキュー長ベースのものがある他、今回の用途だとKubernetes Workloadという他のPodの数に応じてスケールするトリガーが一番近いですが、Slack主導の起動には使えないのと、トリガー元と先両方のPodが同じnamespaceにある必要があったことで断念しました。
そこで、思い切ってカスタムのExternal Pushトリガーを自作することにしました。
External Pushは他のトリガーと同じくScaledObjectでのトリガー指定の一種ですが、KEDAの外部のgRPCサーバーとしてストリームによる起動停止の指示を出す他ポーリングでのメトリクス応答を行うことでスケールを可能とします。
今回作成したExternal Push scalerは、HTTP APIで起動リクエストを受け付けてその内容をKEDAに伝えるという仕組みとすることで、他ワークロードとの連動やSlackからの起動要求を扱えるようにしました。
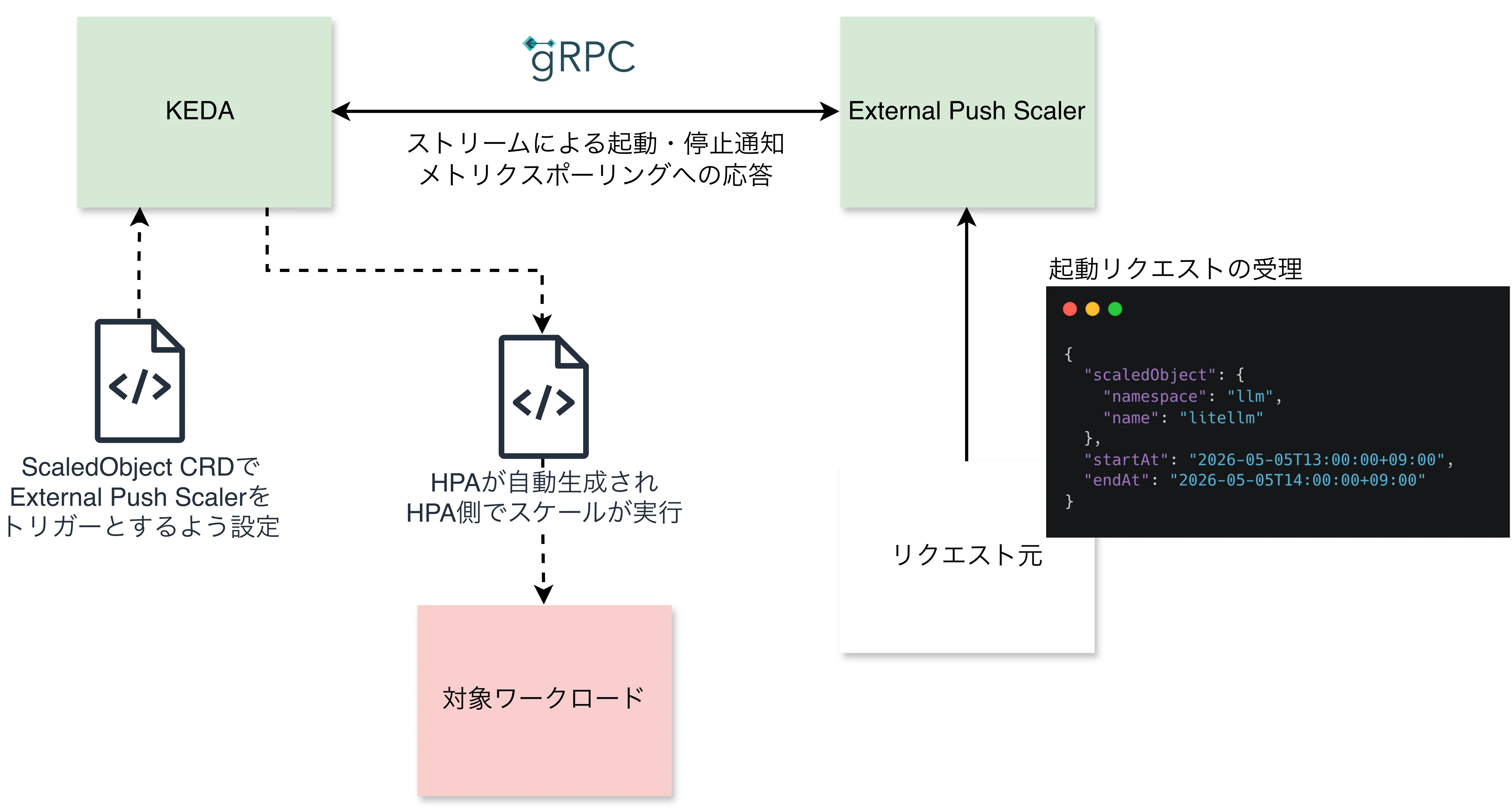
自作External Push scalerの実装
自作した keda-launcher-scaler はかなり素朴な仕組みです(GitHub・Dockerhub)。
HTTPで以下のような起動リクエストを受け付け、受け付けた起動リクエストを内部状態として保持した上でKEDAへのgRPCサーバーとして動きます。
{ "requestId": "litellm-20260505130000", "scaledObject": { "namespace": "llm", "name": "litellm" }, "startAt": "2026-05-05T13:00:00+09:00", "endAt": "2026-05-05T14:00:00+09:00"}ポイントは、起動要求を単発イベントとしてではなく「時間限定のウィンドウ」として扱っていることです。 例えば1時間LiteLLMを起動しておきたいなら、単に1回スケールアウトのきっかけを与えるのではなく、その1時間は対象をactive扱いにし続けます。 これにより、未来の起動予約や延長といった要件にもそのまま対応できるようになります。
Slack Appからの起動要求はこのAPIに送る形にすればよく、ワークロードに連動して起動する場合も合わせてこのAPIに送る形にすればよいです。
この際、ワークロードがいつ終わるかわからないことが多いため、ワークロードのサイドカーコンテナとして起動予約を延長し続けるクライアントをおく形としています。 このクライアントはサーバーと同じレポジトリで実装しており以下のように簡単なマニフェストで実現しています(Dockerhub)。
# 10秒毎に1分間の起動要求を送り続けるサイドカーコンテナinitContainers: - name: litellm-launch-requester image: 7750koutarou/keda-launcher-client:latest env: - name: RECEIVER_URL value: http://keda-launcher-scaler.kube-system.svc.cluster.local:8080 - name: SCALED_OBJECT_NAMESPACE value: llm - name: SCALED_OBJECT_NAME value: litellm - name: REQUEST_INTERVAL value: 10s - name: REQUEST_DURATION value: 1mSlack Appによる手動起動
Slack Appに関しても自前で実装しており、Goのslack-go/slackモジュールを使って実装しています(GitHub・Dockerhub)2。
スラッシュコマンドによって以下のようなモーダルが開き、起動することができます。
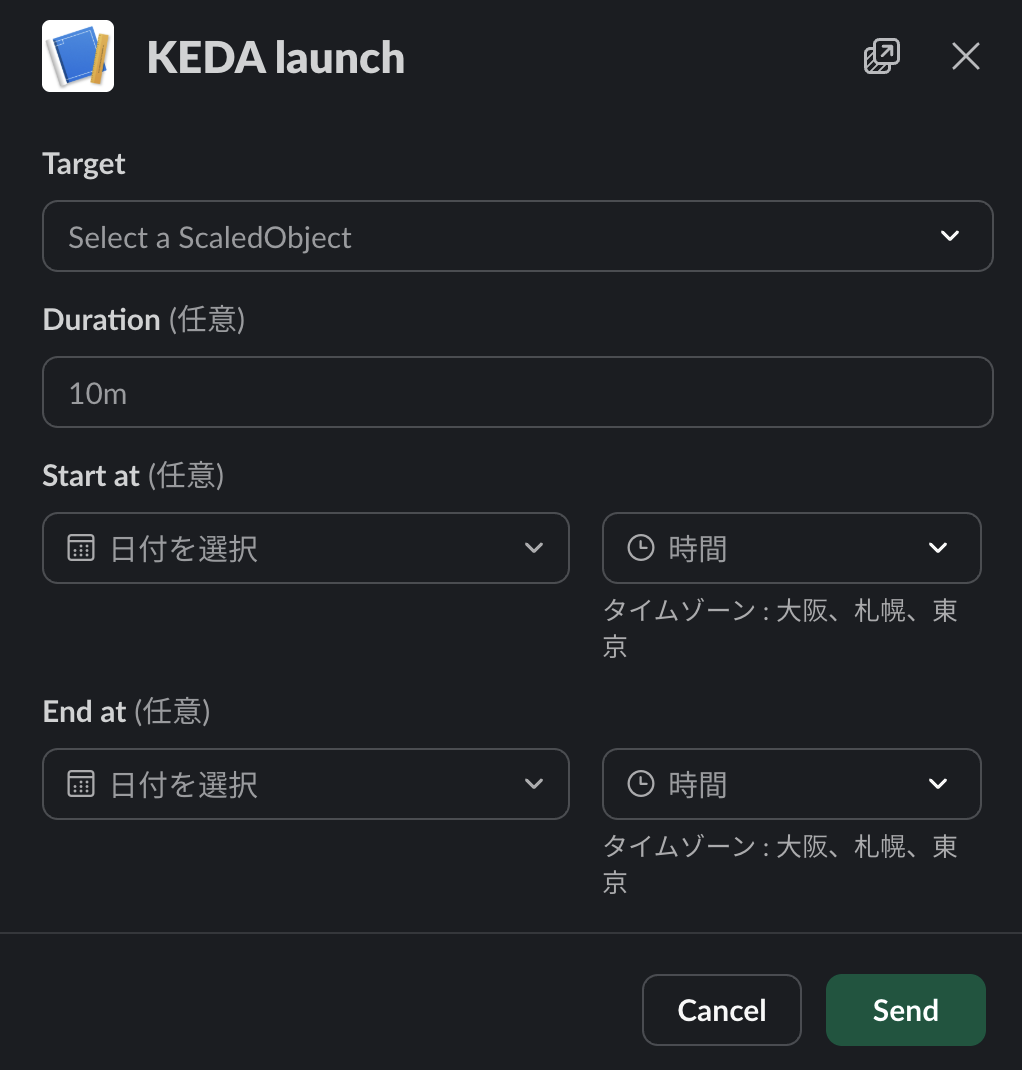
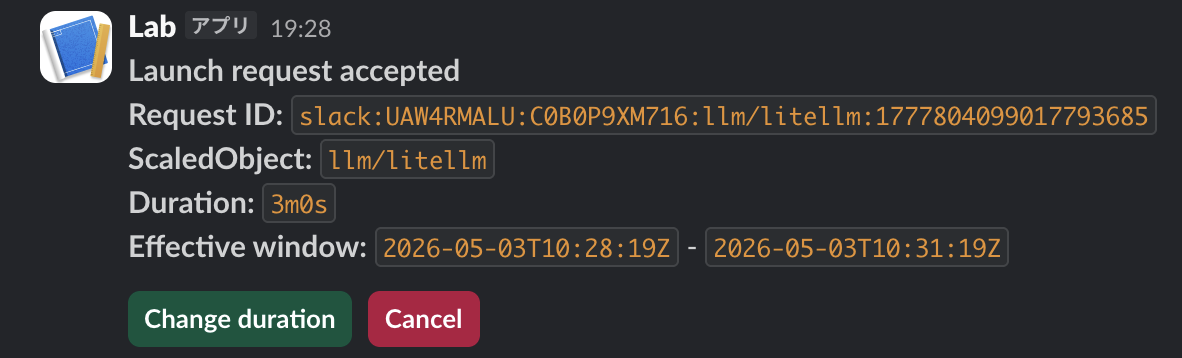
また、時間の変更や停止についてもSlackから行えるようにしています。
実行例
以上のような構成で実際にLiteLLMを起動してみると、以下のような流れになります。
- あらかじめLiteLLMに対してKEDAのScaledObjectを作成しておく
- LLMワークロードのサイドカーやSlack Appから自作のExternal Push scalerに起動要求を送る
- LiteLLMが起動しAurora Serverlessへの接続が発生する
- Aurora Serverlessが起動する
- ワークロードが終わるか、起動要求の終了時間がくるとLiteLLMが停止する
- 5分後にAurora Serverlessも停止する
実際にSlack Appから起動要求を送った際のevent log配下の画像の通り(送ったリクエストは前のセクションのスクショを参考)であり、送ったリクエスト通りにLiteLLMのPodが起動・停止しているのがわかります。
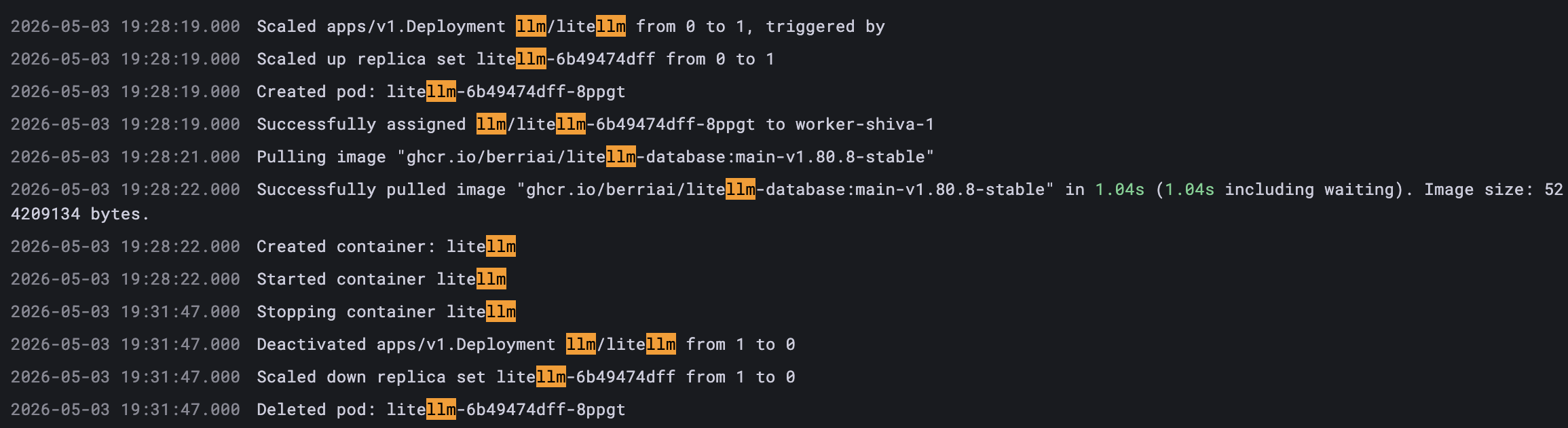
また、Aurora Serverlessについても、LiteLLMが起動したタイミングで起動し、停止してから5分後に停止しているのがわかります。

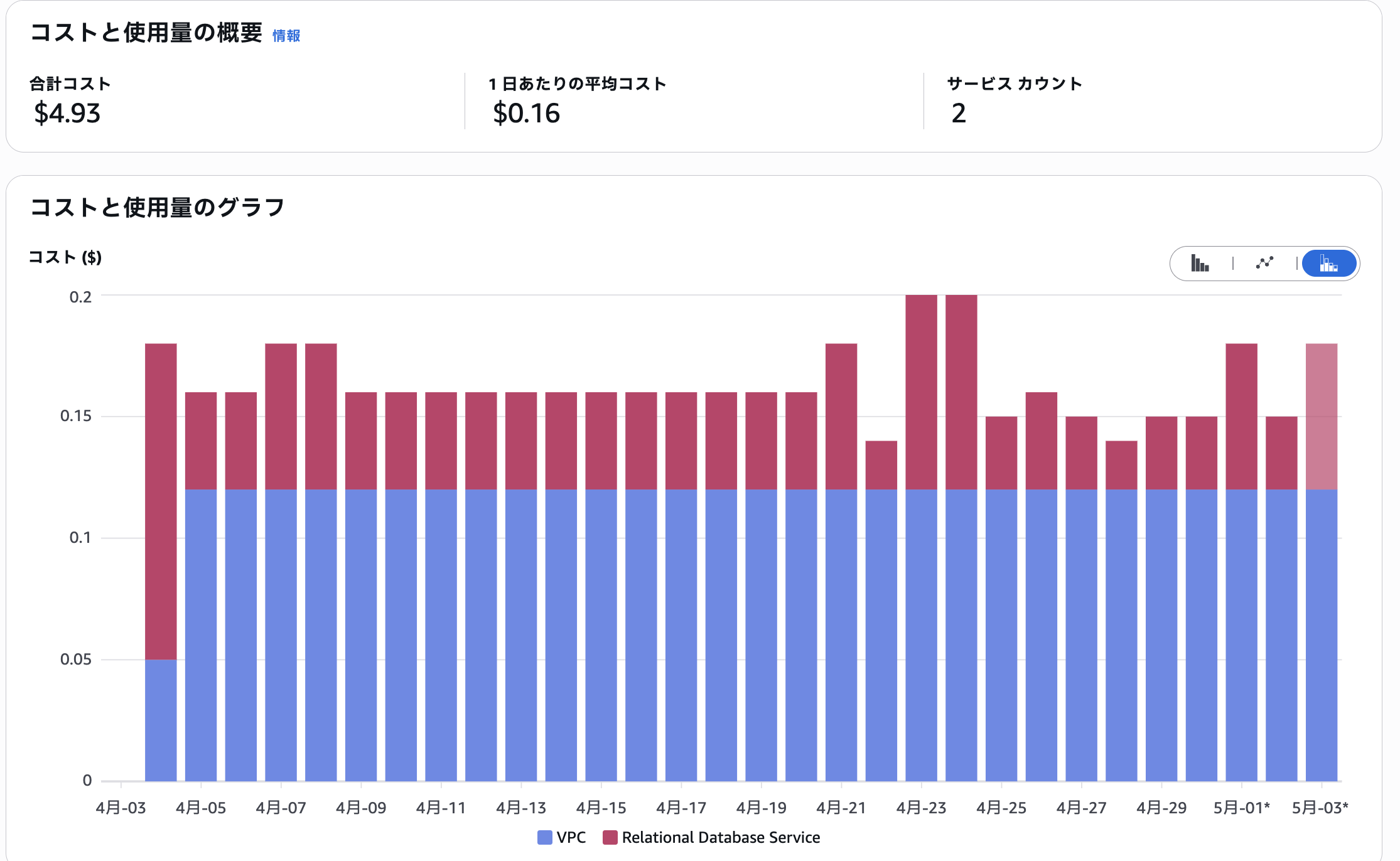
この仕組みを活用して1ヶ月運用した際の実コストが以下の通りです。 もちろんLLMワークロードがまだほぼないという前提ではありますが、月700円程度(パブリックIPを除いたRDS分だけで見ると200円程度)と常時起動させた場合と比べてかなりコストを抑えられているのがわかります3。
まとめ
今回は、宅鯖のLLM・MCPゲートウェイとしてLiteLLMをKubernetes上にデプロイし、Aurora Serverlessと組み合わせた永続化構成を作りました。
その上で、コストを念頭にしたAurora Serverlessの0スケールを活かすために、LiteLLM本体もKEDAで必要なときだけ起動するようにし、さらに標準scalerだけでは扱いづらい起動条件を補うために、時間限定の起動要求を扱うExternal Push scalerを自作しました。 また、Slack Appを組み合わせることで、ワークロードによる自動起動と人間による手動起動を同じ仕組みに統一できました。
結果的にお手軽価格で宅鯖環境としては十分なLLM基盤を構築できたのではないかと思います。
以降はこの基盤によるLLMワークロードの拡充の他、LiteLLMの機能をより活用していこうと思います。